1The idea, in plain English
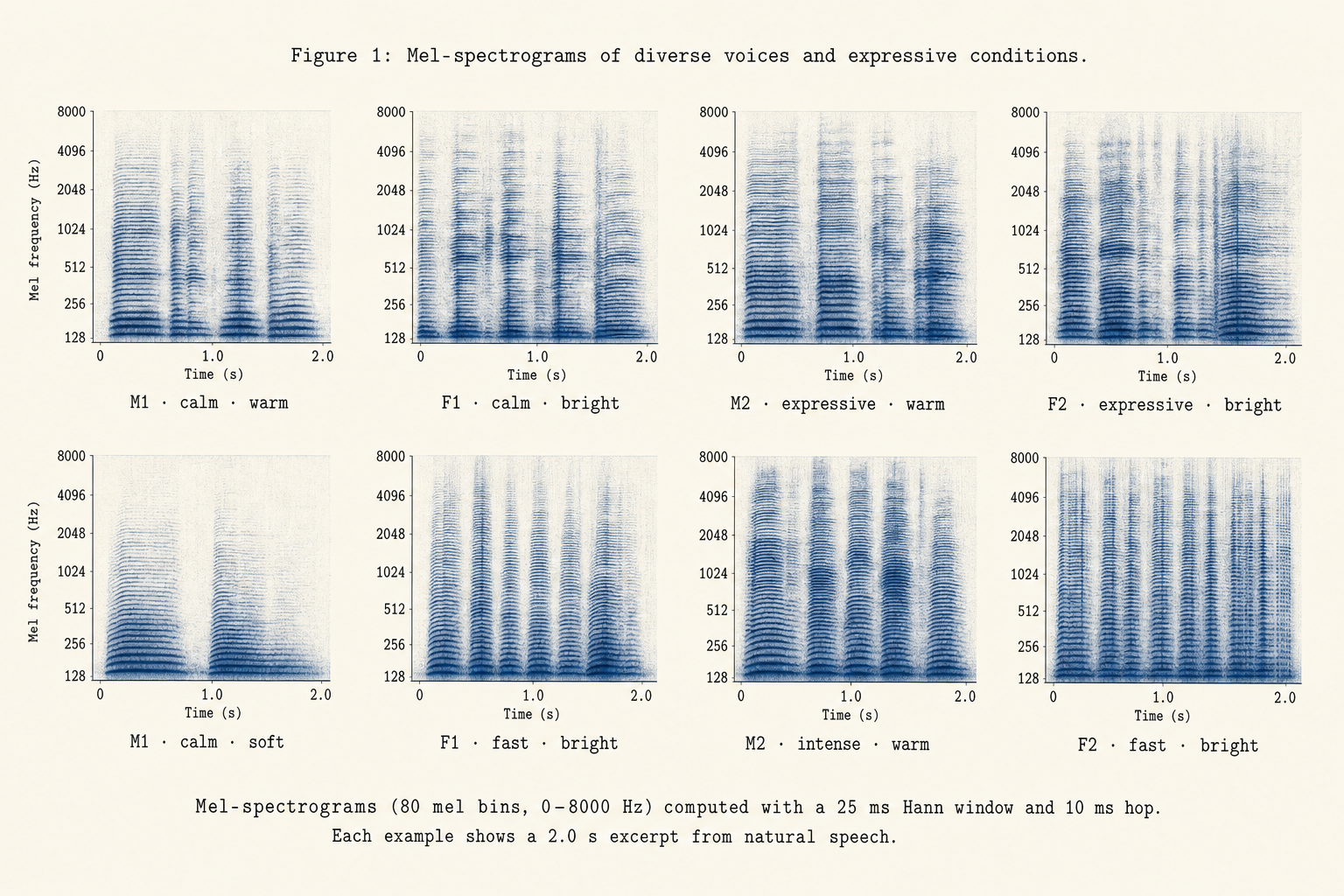
Modern computers can already produce speech that sounds human. The hard part is doing it cheaply and fast enough to use everywhere — not just in a data centre. Aayush TTS is engineered for exactly that: it runs on the kind of processor in an ordinary laptop, with no expensive graphics card.
In plain English
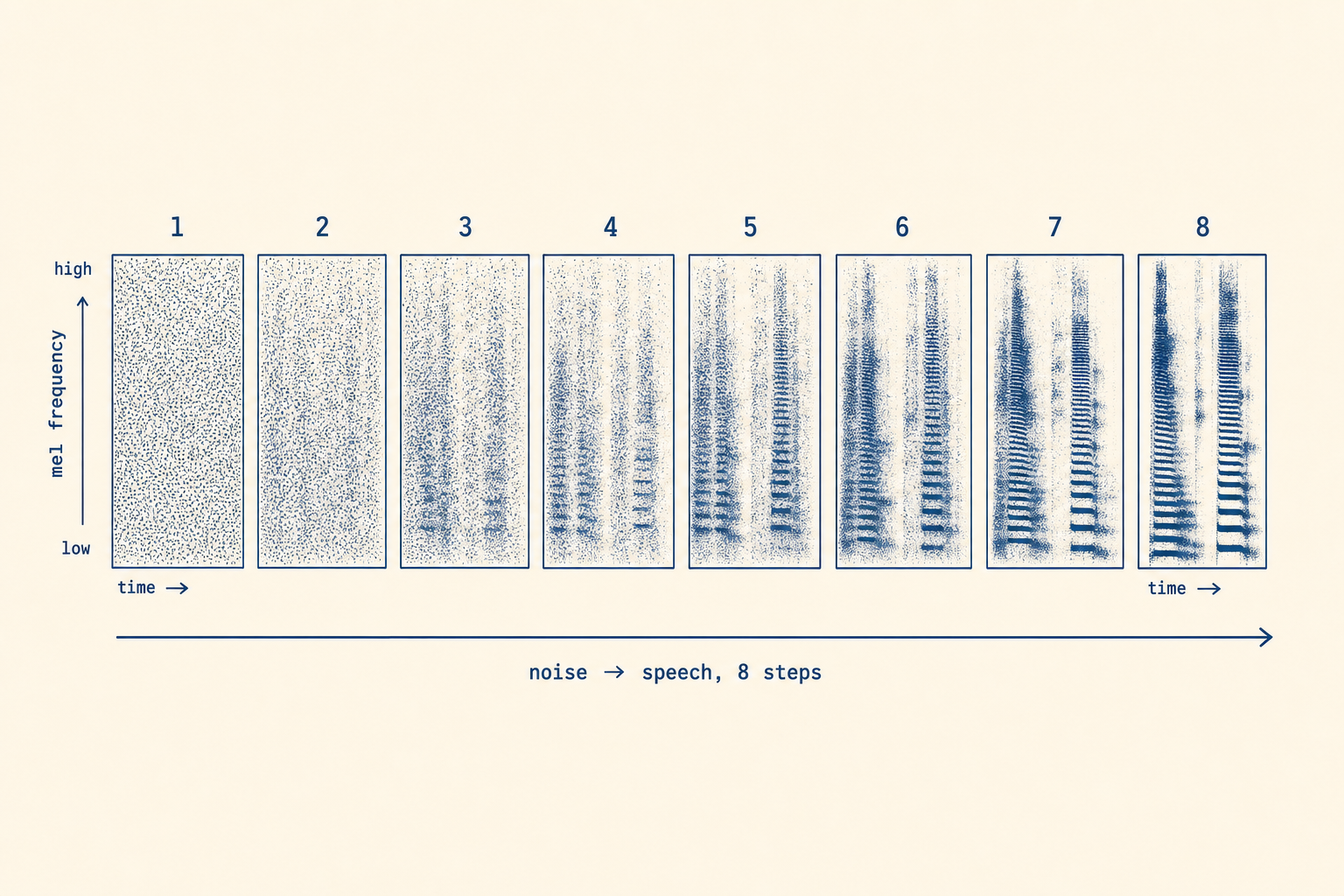
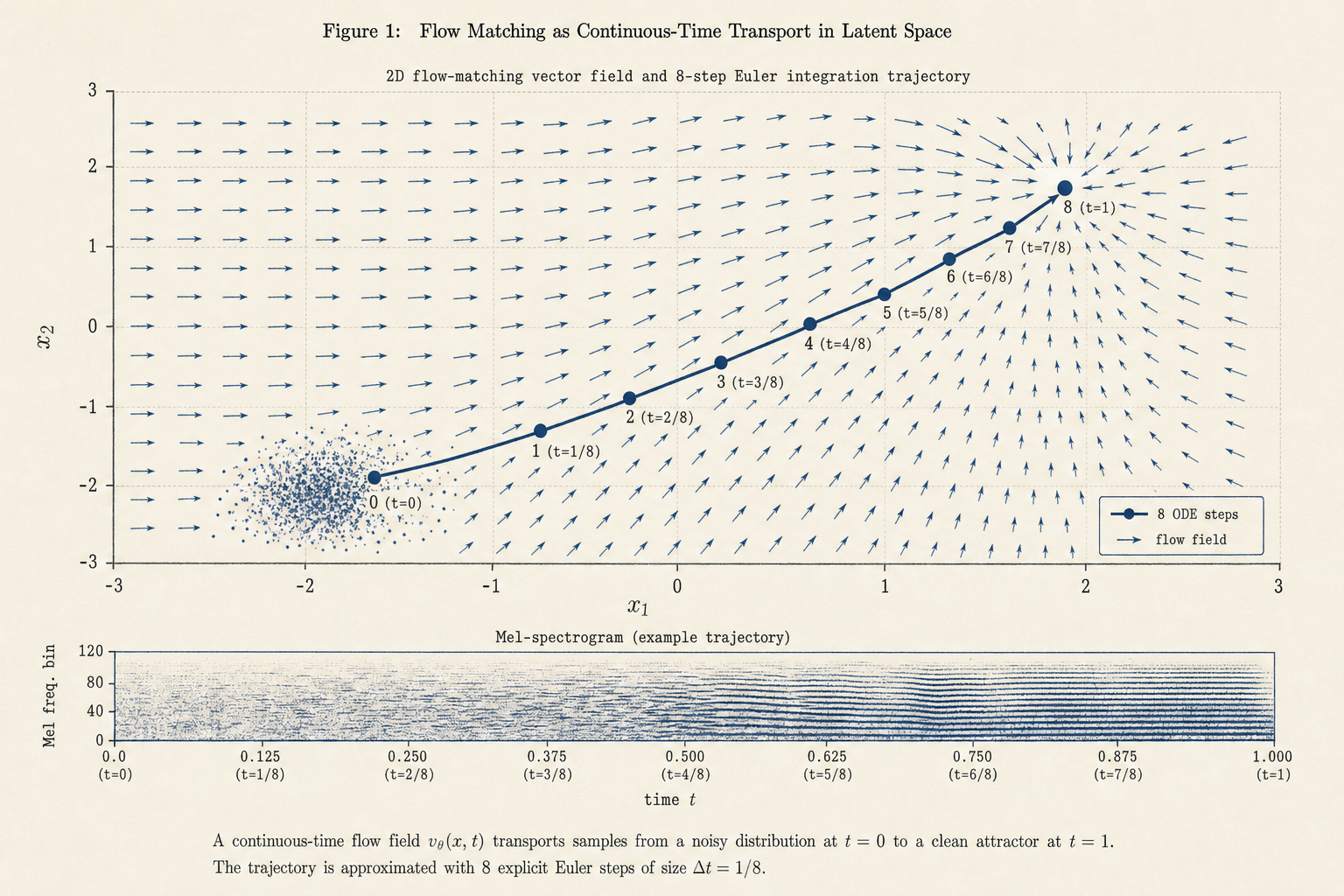
Think of the model as a sculptor. It starts with a block of static (random noise) and, in eight quick passes, carves it into the shape of a voice saying your words. Most systems take hundreds of passes; ours takes eight — which is why it can keep up in real time on a normal computer.